Background
While reading novels from this author, there are complains about the word’s quantities from the author becomes lower & lower.
Due to the curiosity, I decided to spend some time for studying whether the comments are fair or not. In order to do this, I will scrape the novel’s content page, sum up words from each chapter, and group them by month & year. Finally, I will plot them as a graph for further analysis.
During this studying, Chatgpt helps me a lot. It is much better than I thought.
Summary first
- In short, the comments are indeed fair & true.
Below is the plotted graph for the novel “万古第一神”. The x-axis is date while the y-axis is number of words. Since the data source is up to 6 APR 2023, the last data point is not true. But, even ignoring the last data point, the quantity is really in a downtrend at all.
- How about the second book from the same author?
There are also complains about the focus of the author has been changed from “万古第一神” to “太古第一仙”. However, this is both true, and false. As you see, the word’s quantity of “太古第一仙” is also in downtrend.
But, indeed, the focus of the author had been shifted. As you see, the word’s quantity for “太古第一仙” is higher than “万古第一神” significantly.
How to do?
Given the content page, the methodology is simple:
- Get all chapter’s link (The html TAG)
- Get title attribute from each chapter link
- Get the word count & timestamp from the title attribute
- Sum up the word count per month & year.
- Convert the data to CSV
- Save them in google spreadsheet, and plot the graph accordingly
Get all chapter’s link
Since Chatgpt refused to scrape the website due to the regulations etc. So, I do it manually by using xpath.
Turn on the debugger, and locate the chapter link
Right click, and copy the xpath of this element, which is
/html/body/div[5]/dl[2]/dd/a[1]
Then, we can get all chapters within this volume, by using$x(XPATH)in the console.
As there are 2 volumes, we will need to repeat this process, and concatenate the chapters accordingly.
Get title attribute from each chapter link
As title includes the data we need, we need to get title from the element.

Get the word count & timestamp from the title attribute
Given a title like this 第1章 伴生空间的十颗蛋\r字数:2859\r更新日期:2019-07-04 13:59:00, we will need a regex to extract the word count, and the timestamp. That’s Chatgpt work :)


So, let’s make use of them for extracting the word counts & timestamp in the console.

But, the data type of them are all string. We need need to convert them accordingly. For number, we just need Number. But, for the date string, we need something more. Again, this is Chatgpt’s work.
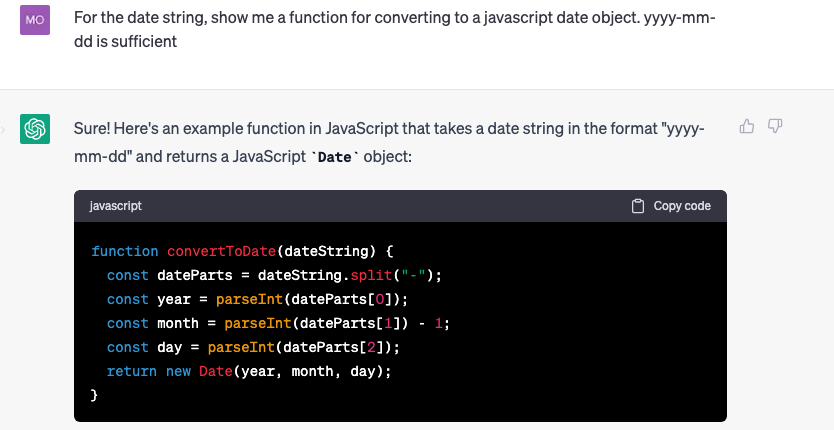
Although the function I am using is different from the chatgpt, the idea is the same.
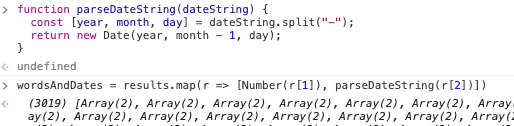
Sum up the word count per month & year
After having the words and dates, I tried multiple ways for asking Chatgpt to write me a function for sum up the words by month and year. None of them fits my need. Therefore, I randomly amend one from the Chatgpt’s answer.
function sumWordsByMonth(wordsAndDates) {
const wordCountByMonth = {};
wordsAndDates.forEach((wordAndDate) => {
const [word, date] = wordAndDate;
const key = `${date.getFullYear()}-${date.getMonth() + 1}`;
if (!wordCountByMonth[key]) {
wordCountByMonth[key] = 0;
}
wordCountByMonth[key] += word;
});
return wordCountByMonth;
}
Then, we will need to encode the result in JSON format. Otherwise, it is hard to copy, and paste to Chatgpt later on.
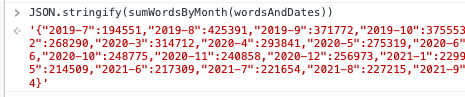
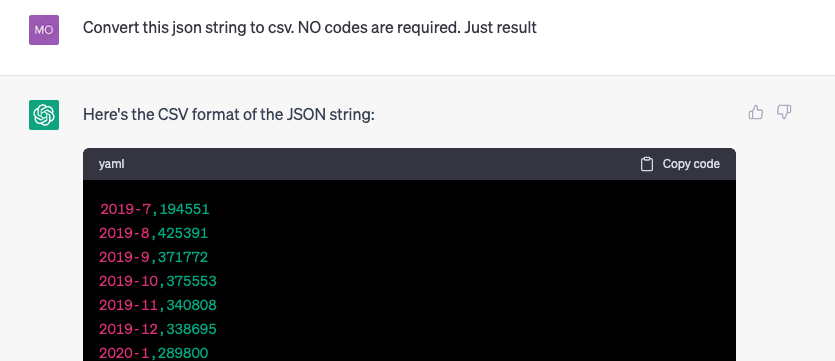
Convert the data to CSV
Chatgpt can do the work properly.

Save them in google spreadsheet, and plot the graph accordingly
As titled. For the final results, see summary section above
沒有留言:
張貼留言